Chapel 2.0: Scalable and Productive Computing for All

Chapel Language Blog
By Daniel Fedorin
Today, the Chapel team is excited to announce the release of Chapel version 2.0. After years of hard work and continuous improvements, Chapel shines as an enjoyable and productive programming language for distributed and parallel computing. People with diverse application goals are leveraging Chapel to quickly develop fast and scalable software, including physical simulations, massive data and graph analytics, portions of machine learning pipelines, and more. The 2.0 release brings stability guarantees to Chapel’s battle-tested features, making it possible to write performant and elegant code for laptops, GPU workstations, and supercomputers with confidence and convenience.
In addition to numerous usability and performance improvements — including many over the previous release candidate — the 2.0 release of Chapel is stable: the core language and library features are designed to be backwards-compatible from here on. As Chapel continues to grow and evolve, additions or changes to the language should not require adjusting any existing code.
Those new to Chapel might be wondering how the language came about. Chapel was pioneered by a small team at Cray Inc. who wanted to help anyone make full use of any parallel hardware available to them — from their multicore laptop to a large-scale supercomputer.
What Are People Doing With Chapel?
As I mentioned earlier, Chapel is being used for a diverse set of production-grade applications; these applications have guided the language’s development, pushing it to grow and support real-world computing workloads.
Arkouda: Interactive Data Analysis at Scale
Arkouda is one exciting application of the Chapel language. It is an open-source data science library for Python written in Chapel. Arkouda enables users to interactively analyze massive datasets. Using Chapel enables Arkouda to scale easily; as a concrete example, its argsort operation, written in around 100 lines of Chapel code, was able to sort 256 TiB of data in 31 seconds, a rate of 8500 GiB/s! That throughput was achieved by scaling Arkouda to 8192 compute nodes on an HPE Cray EX using its Slingshot-11 network. The scaling was made possible through Chapel’s built-in support for multi-node execution.
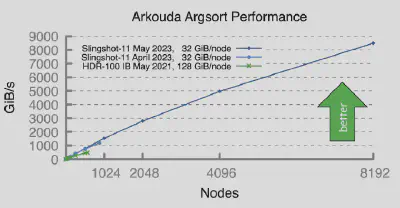
argsort functionArkouda allows data scientists to iterate at the speed of thought, even with datasets spanning terabytes of data — scales that could never fit into the memory of a single machine.
All the performance and scalability of Chapel does not come at the cost of convenience or ergonomics. David Bader, the NJIT professor leading development of the Arachne Arkouda module for scalable graph algorithms, has this to say about the language:
Chapel serves as a powerful tool for the rapid development of scalable graph analysis algorithms, standing alone in its capability to enable such advancements.
CHAMPS: A Framework for Computational Fluid Dynamics
Another excellent example of Chapel’s ergonomics is CHAMPS, a software framework focused on three-dimensional, unstructured computational fluid dynamics. CHAMPS is made up of over 125,000 lines of Chapel code, making it the largest project written in the language. The principal investigator of CHAMPS, Éric Laurendeau, has remarked on the productivity gained by switching to Chapel:
We ask students at the master’s degree to do stuff that would take 2 years and they do it in 3 months. . . . So, if you want to take a summer internship and you say, . . . “program a new turbulence model,” well they manage. And before, it was impossible to do.
At the time of this quote, CHAMPS was 48k lines of code, a near threefold decrease from the 120k lines of its C-based predecessor. In addition to this, CHAMPS improved upon its predecessor by extending the fluid dynamics simulations to use distributed memory and be three-dimensional, unstructured, and multi-physics. Each of these advances represented a step up in complexity. Despite this, the Chapel-based CHAMPS proved to be easier to learn, program, and maintain.
Coral Biodiversity Computation
One area particularly suited for parallel computing — and one at which Chapel excels — is image analysis. Scott Bachman, an oceanographer and climate scientist, learned Chapel from the ground up to develop software for coral reef biodiversity analysis. Scott made use of Chapel’s parallel programming features to develop efficient algorithms for finding ideal spots for coral preservation. He did so by analyzing an intricate high-resolution satellite image of an ocean island. Below is how Scott described his experience:
I have now written three major programs for my work using Chapel, and each time I was able to significantly increase performance and achieve excellent parallelism with a low barrier to entry. Chapel is my go-to language if I need to stand up a highly performant software stack quickly.
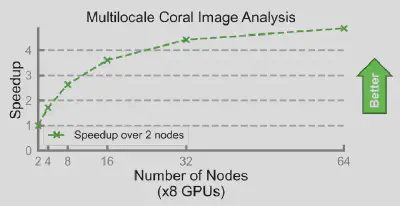
By making use of parallelism, Scott was able to greatly improve on existing, serial implementations in Matlab. From Scott’s presentation at SC23:
Previous performance (serial, MATLAB): ~ 10 days Current performance (360x cores, Chapel): ~ 2 seconds Roughly 5 orders of magnitude improvement
It’s also worth highlighting Chapel’s portability. Scott wrote and tested his programs on a laptop. With only minor modifications — including tweaks to enable GPU support — his code was able to be executed on Frontier, the fastest system in the TOP500, and the only one in that list to reach a computation speed of one exaflop. Scott’s code distributed the problem across several of Frontier’s nodes, and across each of the eight GPUs present in each node. By doing so, it was able to achieve a massive speedup: back-of-the-envelope estimations suggest that Scott’s program would take 648 hours to run on an 8-core CPU, whereas the 64-node version on Frontier ran in 20 minutes. In other words, what would’ve taken an 8-core machine almost a month was sped up to less than the length of a lunch break.
In addition to being a significant performance win, this use case highlights an essential aspect of Chapel: the tools that Chapel provides to developers can be used for programming diverse parallel hardware. Programs can be scaled from a laptop, to a GPU-enabled cloud instance, to a supercomputer, using the same language concepts and features. At the same time, Chapel programs are vendor-neutral — they work on a variety of processors, networks, and GPUs. As a concrete example, GPU-enabled Chapel programs work with both NVIDIA and AMD GPUs.
A Language Built with Scalable Parallel Computing in Mind
Chapel was built specifically for parallel computing at scale, guided by experts and real-world high-performance use cases. Because of this, the language has many unique features. These features interconnect to form a consistent and general model for programming diverse parallel hardware, as I alluded to in the previous section. To get a taste of Chapel, take a look at the following serial program:
var Space = {1..n};
var Dst, Src, Inds: [Space] int;
initArrays(Src, Indices); // populate input arrays with data
for i in Space do
Dst[i] = Src[Inds[i]];
This program copies elements from an integer array Src to another integer array Dst. However, it reorders the numbers it copies — the third array, Inds, contains the destination indices for each source index. In other words, destinationIndex = Inds[sourceIndex].
When trying to improve the performance of a program like this, one important thing to consider is that today, even the CPUs of relatively cheap consumer laptops have multiple processor cores. This means that they support parallelism. To tweak the above program to allow it to make use of multiple CPU cores, it’s only necessary to change the for to a forall. If you were to run this on your 8-core M1 Mac, the iterations of the loop would be divided between those cores, likely resulting in a noticeable speedup over the original for-loop.
var Space = {1..n};
var Dst, Src, Inds: [Space] int;
initArrays(Src, Indices);
forall i in Space do
Dst[i] = Src[Inds[i]];
With just one more tweak — the addition of an on statement — the above program can be made to execute on a GPU:
on here.gpus[0] {
var Space = {1..n};
var Dst, Src, Inds: [Space] int;
initArrays(Src, Indices);
forall i in Space do
Dst[i] = Src[Inds[i]];
}
In this case, iterations of the loop will be executed in a massively parallel fashion by the multiple threads of the GPU. I covered Chapel’s GPU support in some detail in Introduction to GPU Programming in Chapel.
To scale the program to something like a cluster, cloud instance, or supercomputer, the programmer has to make use of several compute nodes at the same time. In this example, that can be achieved by asking Chapel to distribute the arrays across all compute nodes available to the program. When doing so, Chapel divides the iterations of the loop — as well as the array data itself — across the nodes’ memories and processors.
use BlockDist; var Space = blockDist.createDomain(1..n); var Dst, Src, Inds: [Space] int; initArrays(Src, Indices); forall i in Space do Dst[i] = Src[Inds[i]];
With additional tweaks, the multi-node and multi-GPU versions of this program can be combined to distribute computations across all GPUs in an entire cluster. These are the exact sorts of changes that were made to Scott Bachman’s Coral Reef software above to make it run on Frontier.
The main takeaway is that the same tools — forall loops and on statements — interplay elegantly to fit a wide variety of use cases. Moreover, they don’t sacrifice performance. The multi-node version of the program above (which is the Bale IndexGather benchmark, by the way), outperforms standard parallel computing technologies:
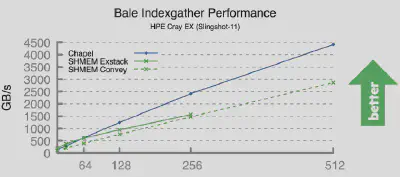
--auto-aggregation compiler flagThe code presented up to this point is far from a complete picture of all of the unique features that Chapel brings to the table; there’s just not enough space here to cover them all. Some other features to check out are:
syncvariables andcoforallloops for explicit parallelism, covered in depth in one of our previous blog posts- reductions, for combining a set of elements into a scalar, covered in another blog post
- promotion, for seamlessly applying scalar functions to multiple elements at once, covered in a third blog post
And those are just the parallelism-specific features! Take a look at the Advent of Code series for a gentle introduction to Chapel, including its general-purpose features.
Rich Tooling Support
Chapel’s 2.0 release also brings improvements to developer tooling. Along with the latest version of the language, the Chapel team is publishing a Visual Studio Code extension for Chapel. This extension provides support for a number of features, including:
- code diagnostics (syntax and semantic errors), including quick fixes
- documentation on hover
- go-to-definition, find references
- linting for common issues using
chplcheck - and much more!
The VSCode extension is an exciting development, bringing a large number of modern editor features to users of Chapel. Much like the features of Chapel itself, there’s simply not enough room in this article to show all of them off. Stay tuned for another article that walks through what the new extension can do in more detail. In the meantime, as a little teaser, here’s a demonstration of hover information and go-to-definition:
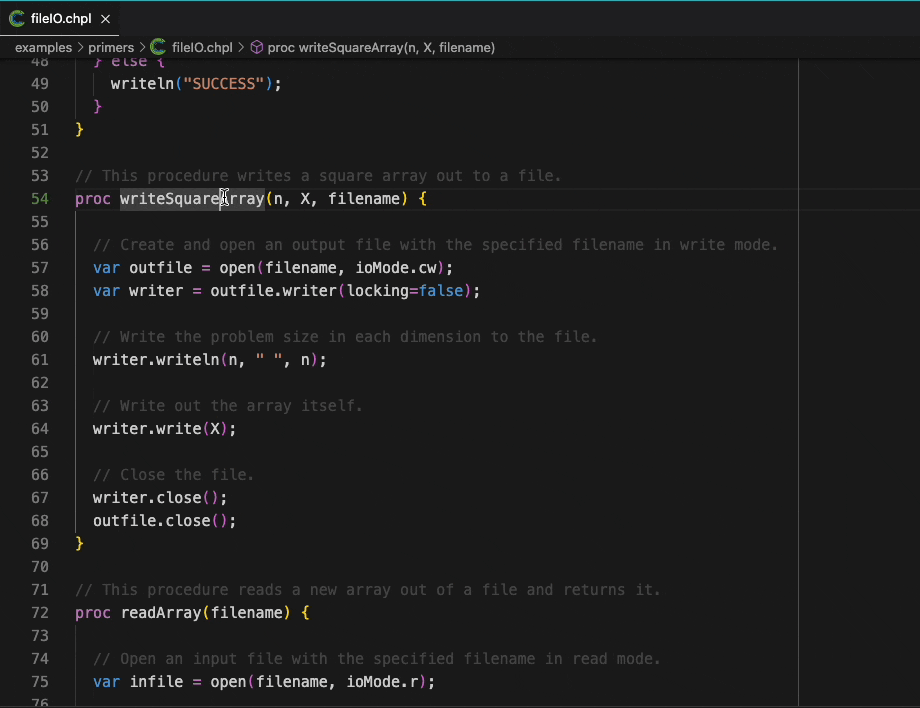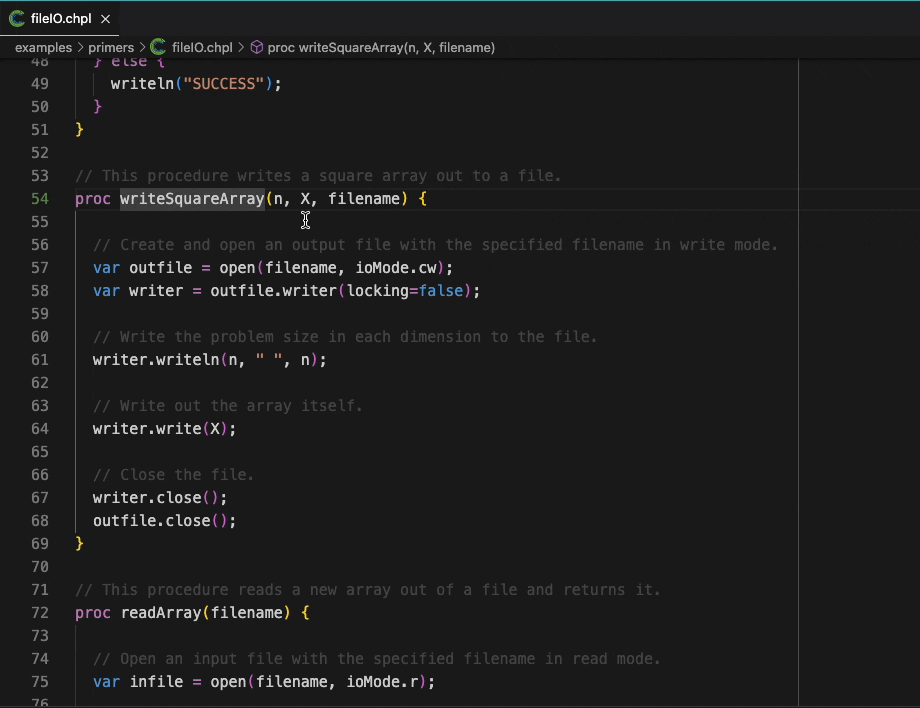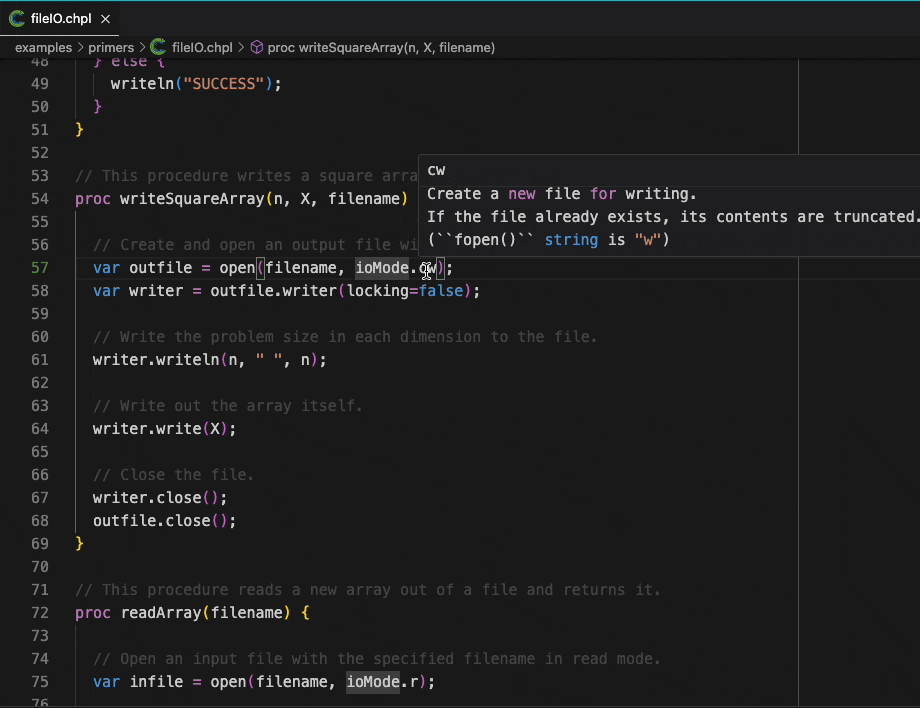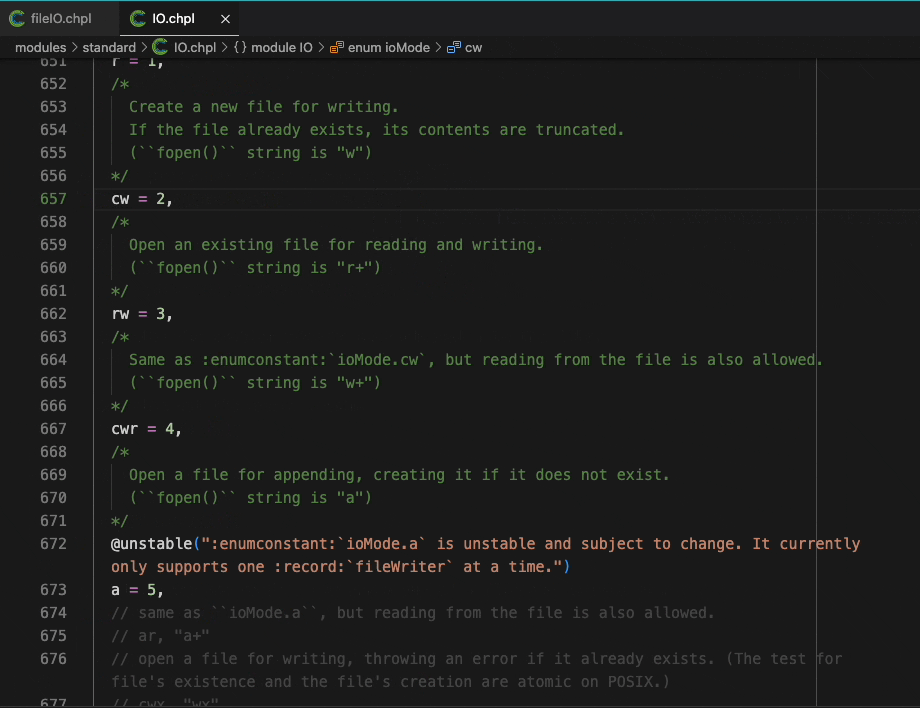
Much of the extension’s functionality is provided by a general tool that uses the Language Server Protocol. This new tool, the Chapel language server, can also be used from other editors. For example, members of the Chapel team use it with Neovim on a daily basis.
Conclusion and Looking Forward
Chapel has supported developers with various computing needs in creating performant and maintainable software since 2015, a track record of nearly 10 years. The 2.0 release represents the culmination of a concerted, multi-year effort to refine Chapel’s core functionality based on these many years of experience. Chapel is now stable, but it is not finished: the language will continue to see performance improvements, new features, and better tooling. Whether you are working with a personal machine or a multi-node cluster, there has been no better time to get started with Chapel to get the most out of your computing hardware.
David A. Bader
Distinguished Professor, Associate Dean for Research, and Director of the Institute for Data Science
David A. Bader is a Distinguished Professor in the Department of Data Science and Associate Dean for Research in the Ying Wu College of Computing at New Jersey Institute of Technology.